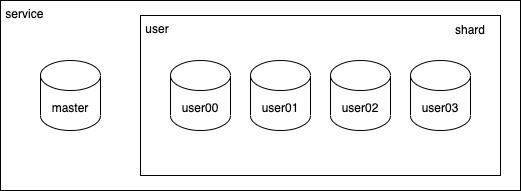
コロプラでは現在新規開発のDBとしてGoogle Cloud Spannerの採用を積極的に行っていますが、それ以前はMySQLを採用し新規サービスを提供してきました。現在も運用中の多くのタイトルでMySQLが利用されています。
MySQLを利用しているサービスは規模によっては垂直/水平分割を併用して運用しています。
分割は負荷に強くなる一方で、不具合の調査などでSQLを用いてデータを調査するなどの運用時のオペレーションのコストがあがってしまいます。
コロプラでは分割されたDBでSQLを用いた調査などの運用業務の改善を社内独自のツールを作って多少なり緩和しているというお話をさせていただきます。
紹介が遅れましたが、コロプラのロン毛といいます。普段は横断系のチームで業務をさせていただいています。
ツールの概要
分割されたMySQLにクエリを投げることに特化しており、名前はNite(ナイト)といいます。※1
Pythonで開発されています。※2
設定ファイルに接続情報を書くことで複数のDBへの接続を簡単に1プロセス上で行えるようになっています。
基本的には参照クエリ専用として作られており、社内ではリードオンリーなユーザーで接続しています。※3
機能説明
いろいろな機能があるのですが、特徴的な機能は大きく下記の3つです。
- 1プロセスで複数DBへ接続できる
- 水平分割されたDBへの横断検索機能
- 検索結果への再検索
簡単ではありますが、各機能について説明させていただきます。
1プロセスで複数DBへ接続できる
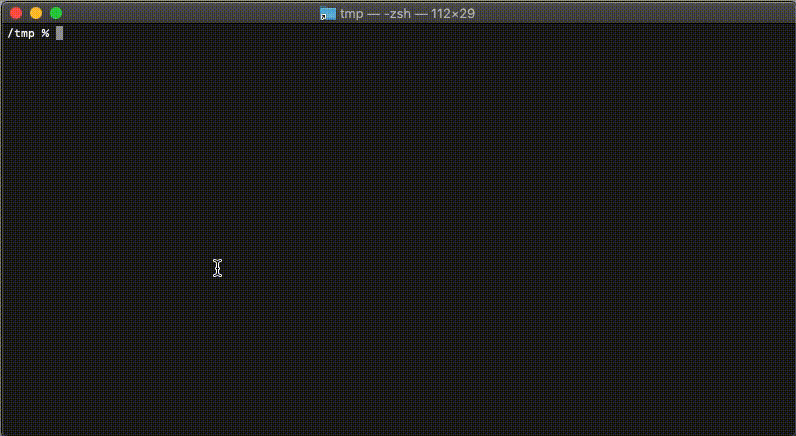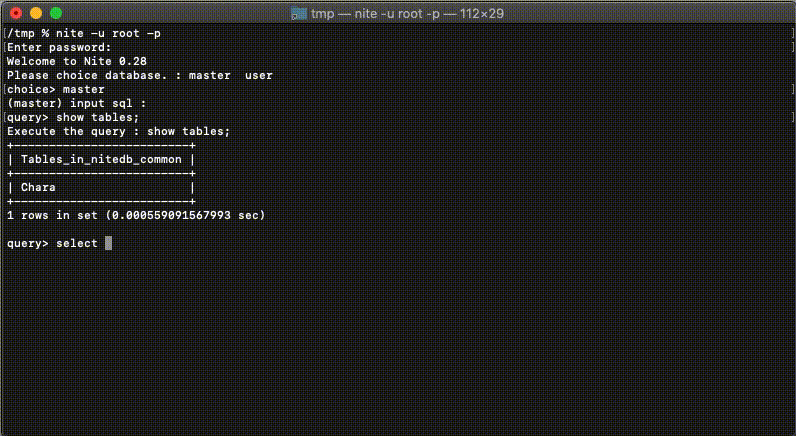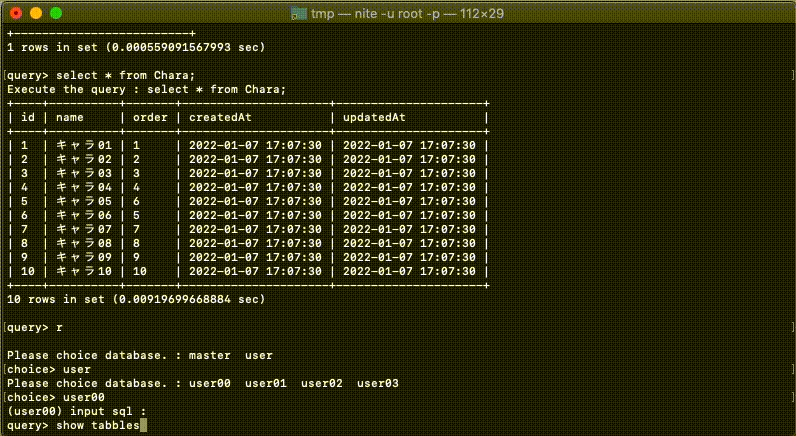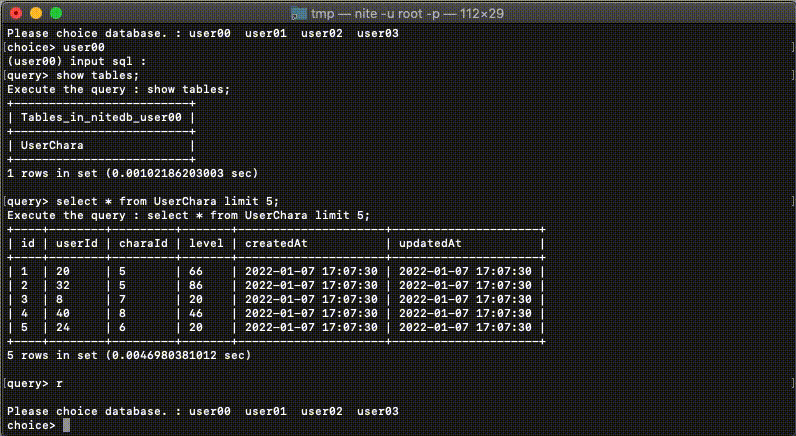
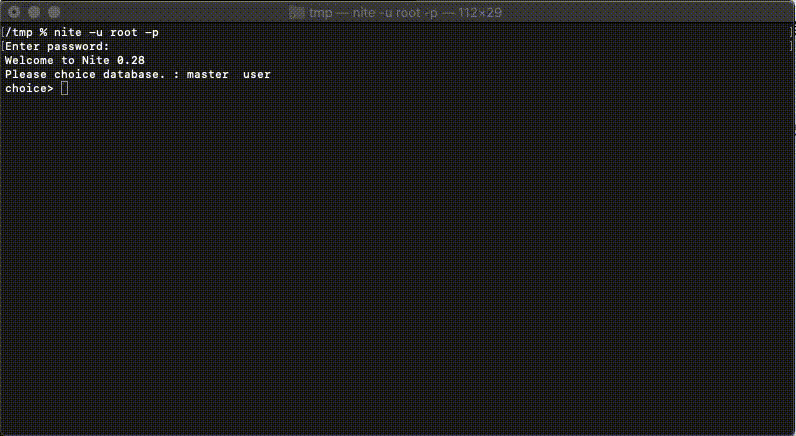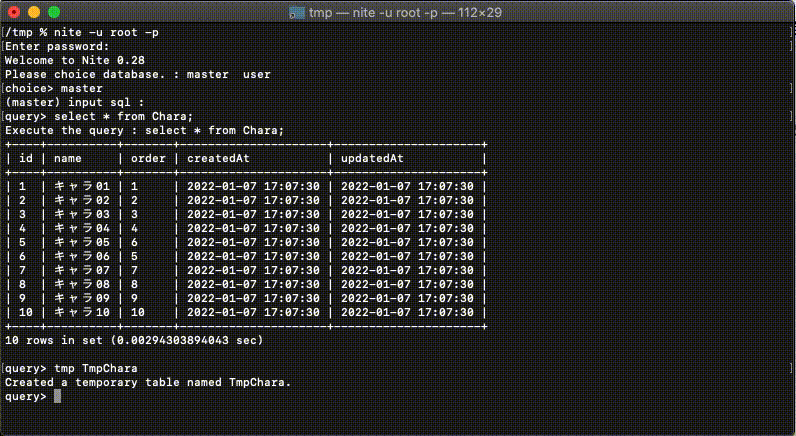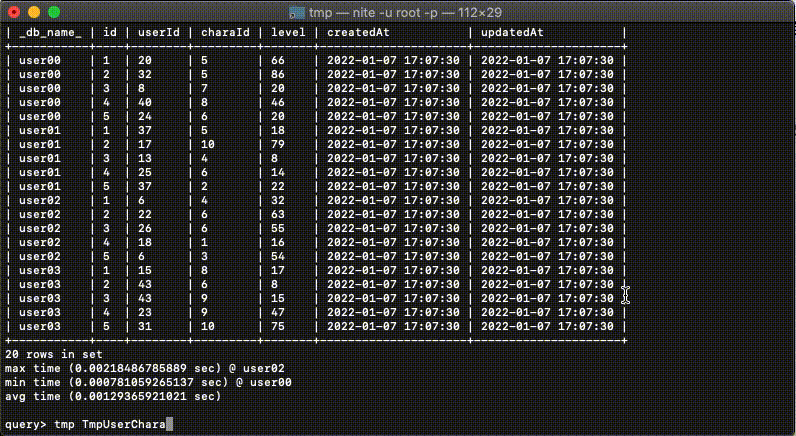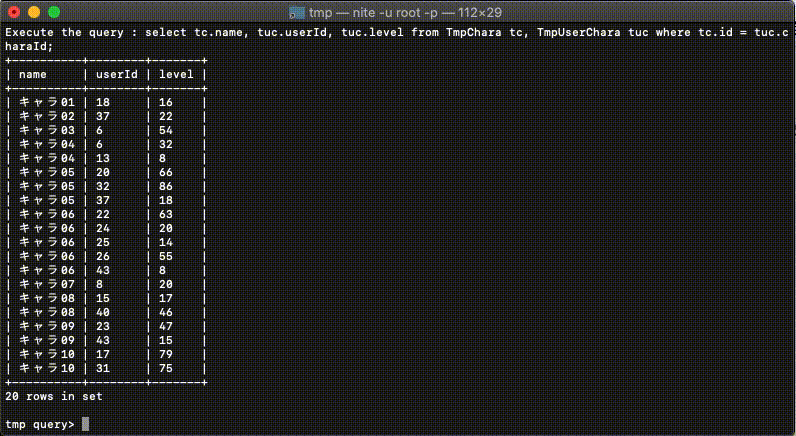
設定ファイルに記載されたDBへの接続をシンプルなコマンドで実現することができます。設定ファイルへの接続はネストして記載できるので水平/垂直分割をわかりやすく設定できます。
水平分割されたDBについては別途グループ化しておくことで水平分割したDBへの検索が便利に行うことができます。
対話形式になっているのですが、DBを選択するモードと、検索するモードなどいくつかのモードに合わせて利用できるコマンドが決まっています。
水平分割されたDBへの横断検索機能

Niteで一番メインの機能です。
複数DBを一気に選択し(階層以下のDBを検索する際は!をつける)クエリを実行すると、選択されたDBに対して並列でクエリを実行し、結果をまとめて表示することが可能です。
どのDBから検索された結果であるのか、というのをわかりやすく表示するために設定されているDBの名前が検索結果に_db_name_というカラムで追加されます。
ここで問題になるのは、いわゆる集計系のクエリの結果なのですが、SQL構文を解釈するのは難易度が非常に高いので、基本は入力されたクエリを各DBに投げた結果をマージするのみというシンプルな作りにしています。
集計関数を使っているんだから、すべてのデータを集計してほしいところですが、DBごとの結果が複数返ってくるので、これではまだ求めている結果は得られていません。
次に説明させていただく「検索結果の再検索」の機能によってある程度のことはこのツールで対応できるようにしています。
検索結果への再検索
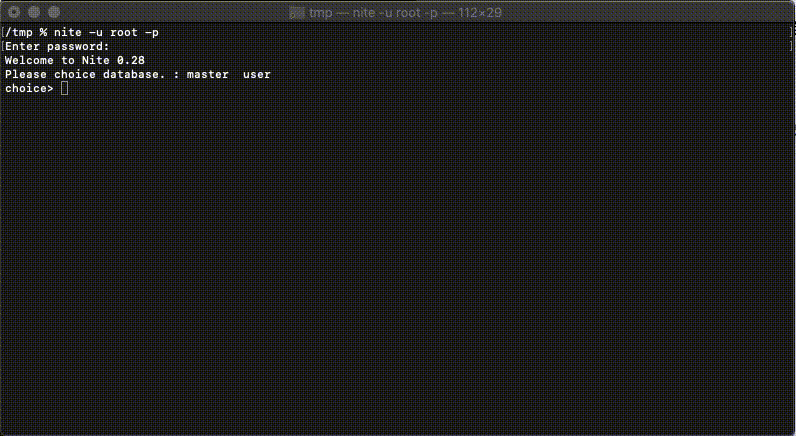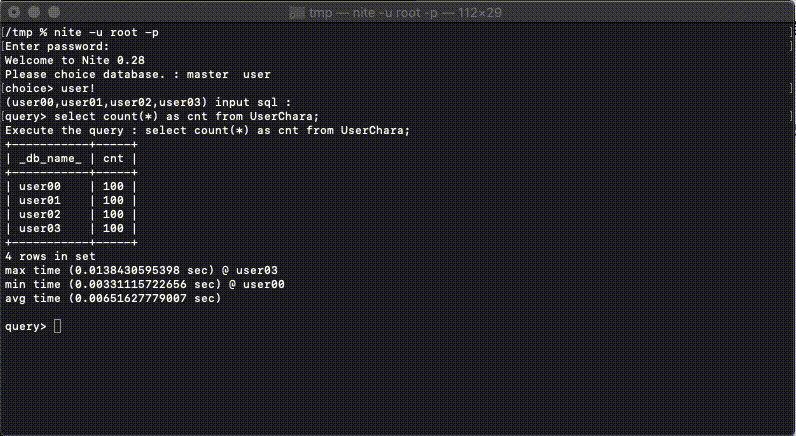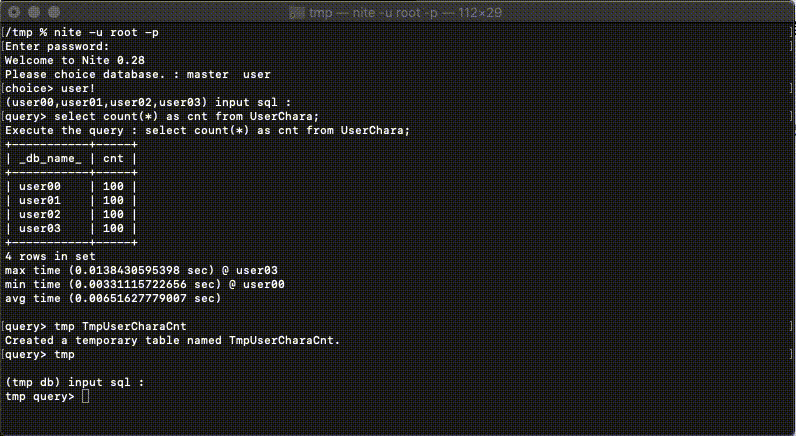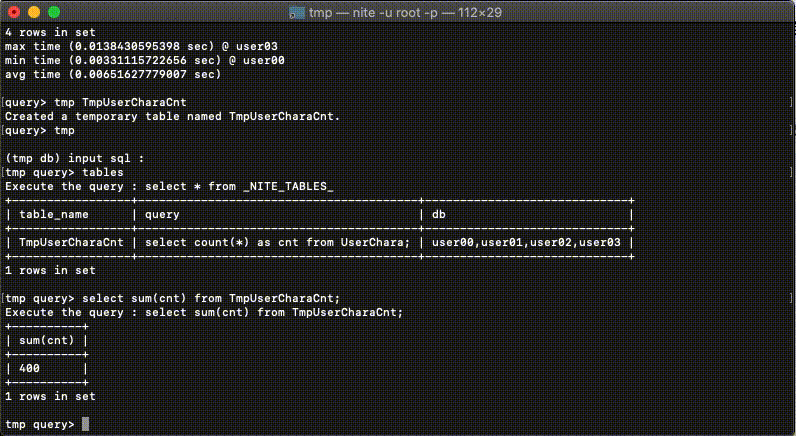
Niteの中にある非常に意欲的な機能です。
検索結果をローカル上のsqliteに新規テーブルとして名前をつけて取り込むことができます。※4
この機能を利用することで、上述させていただいた水平分割されたDBへの集計の検索結果に対しての再集計を実現できます。検索結果の再集計をSQLで、しかも同じプロセス内で行うことができます。
水平分割されたDB内のすべてのデータの平均値をとりたい場合などは、単純に平均値の平均値を算出するだと結果が正確ではないので、各DBで件数と合計値を検索し、合計値を総件数で割って出す必要があります。
また上位100などのランキングのようなデータを検索したい場合には、各DBで上位100を取ってきてマージして、上位100件を再度ランキングする必要があります。
利用者側は分散されたDBに対しての操作を理解している必要がありますが、同一プロセス内でかつSQLで検索結果を再検索できるのは、慣れてしまえば非常に便利です。
その他の機能
上記で説明した以外にも
・検索結果の一部を次のクエリに利用する機能
DBをまたぐケースのサブクエリの代わりとして利用するイメージです
・マクロ機能
よく行う「検索結果への再検索」の流れをマクロとしてファイルに書き出して、再利用などできる
・タブキーによる補完
DB切替時にテーブル名、カラム名を読み込んで補完候補に入れている
など社内での運用に耐えられるように様々な機能が追加されています。
欠点
このツールの欠点はいくつかあるのですが、一番大きい欠点は学習コストだと思っています。
説明のアニメーションを見ていただいた方はわかると思うのですが、mysqlコマンドにはないモードの概念や、(簡単にするように心がけたつもりですが)専用のコマンドを複数覚えなければ快適には利用できません。
導入を検討してもらえそうなプロジェクトには操作の説明会を開催し、導入コストを下げるなど欠点を補う努力をしていました。
最後に
Google Cloud Spannerの採用が進んできており分割されたMySQLの運用割合が減ってきたこと、利用者の要望への対応がほぼ完了したことなどから現在は新機能の追加などは行われておりません。特定のことを便利に行うためのツールとしては完成したと言えるのかなと思っています。
この記事を書かせていただくにあたり、gitの更新履歴を見たのですが、2017年11月に開発を開始して上記で紹介したような主要な機能は半月ほどで開発を行っていたようです。なかなかに入り組んだコードになっているのですが、短期間での開発と考えれば納得ですね。※5
最初のころはオープンソースにしたいな、とかMySQL以外のRDBMSでも使えるようにしたいなという高い志もあったのですが、業務を改善するためにとにかく早く開発する方向に振り切りました。※6
それ以降は社内独自の構成やMySQL独自の問題への対応を開発途中からはためらいなく取り込んだため社外に公開できるツールに至りませんでした。
今回コロプラのエンジニアブログが開設されるにあたり、アイディアを公開することで、開発当初の「オープンソースにしてエンジニアコミュニテイに貢献したい」という思いを少しでも消化できたらなと思い紹介させていただいた次第です。
以上、業務改善のためのツールを作ったお話でした。
最後まで読んでいただきありがとうございます。
※1 水平分割されたDBでの障害調査が大変だった日の夜(night)に衝動的に開発しはじめたのが名前の由来です。筆者はnightという綴りを75%ぐらいの確率でtypoする体質なので綴りを変更しています。
※2 ツールが使われるサーバー上でデフォルトで入っている言語を選定したというのが表向きの理由で、筆者が一番得意な言語を使ったというのが本当の理由です。
※3 更新権限のあるユーザーでDBに接続すれば更新もできてしまうのですが、並列でクエリを投げる機能を利用した際に一部のDBでエラーが起きたときのハンドリングをどうするかはケースバイケースになってしまうと考えたため、更新をサポートしないという割り切りをしています。
※4 sqliteではなくMySQLにするとRDBMSによる構文の差を気にしなくて良いなというアイディアもあったのですが、環境構築の容易さからsqliteを選択しました。
※5 社内のコードを読んだことがある人に対しての完全に純粋な自己擁護です。
※6 言い訳がましく書いてますが、つまるところ両立させる技術力がなかったという話です。